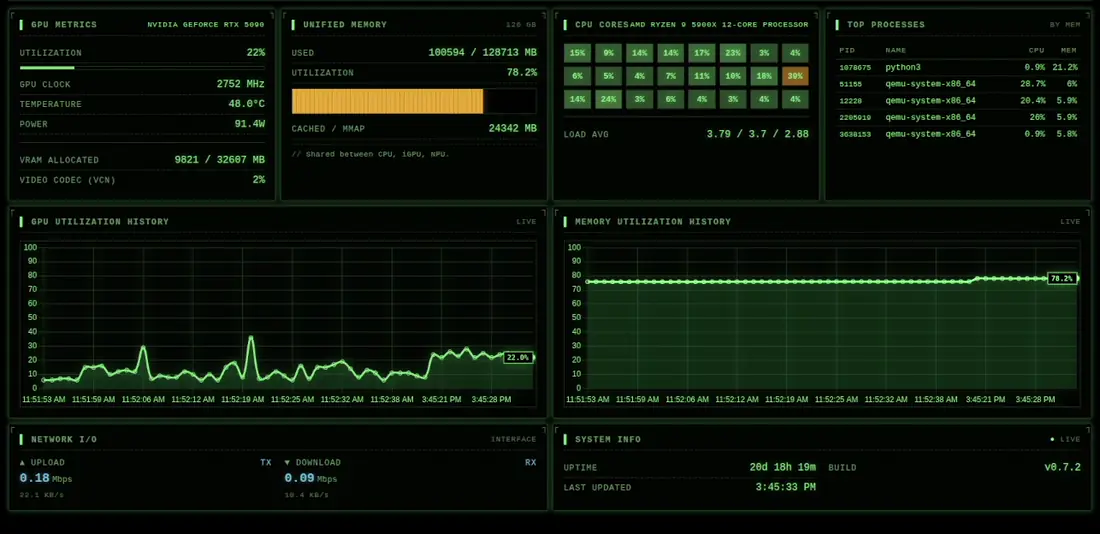
Strix.Monitor
Linux retro-themed h/w monitor w/real-time telemetry & historical data.
Huge LLM context windows are awesome. They're also pointless if you run out of VRAM.
If you’re using cloud AI services this isn’t a concern for you, only hitting subscription limits or surprise overages because you forgot to turn off the extra-tokens-as-long-as-your-credit-card-isn’t-declined setting. But if you’re a local-AI enthusiasts you’ve likely experienced the dreaded OOM (out-of-memory) error. I certainly have, usually when multiple models are loaded. What can I say? I like to multi-task.
A while back I used the same LLMs I was testing to build a custom app to monitor my server’s VRAM from any browser on my LAN – even my phone. Now I’ve open-sourced it (MIT license) for the benefit of my fellow local-AI aficionados.
https://github.com/levanillawafer/strix-monitor
It’s Linux-only – Windows already has plenty of decent monitors – and while designed for the AMD Strix Halo platform it works perfectly well on Nvidia and non-unified memory systems.
Yes, it’s a niche-within-a-niche, but if you occupy that same corner of the Venn diagram as me it comes in handy. And as cloud token costs skyrocket mastering local workflows and hardware monitoring will become a vital skill for anyone running local LLMs alongside cloud frontier models.
Plus, it looks like a Pip-Boy 3000 screen. so you can pretend to check up on your AI agents from a post-apocalyptic setting – which, given the current trajectory of tech, doesn't feel entirely out of reach.
Enjoy.